Natural Language Processing (NLP) is about the processing of natural language by computer. It’s about making computer/machine understand about natural language. Natural language means the language that humans speak and understand.
Natural Language Toolkit (NLTK) is a suite of Python libraries for Natural Language Processing (NLP). NLTK contains different text processing libraries for classification, tokenization, stemming, tagging, parsing, etc.
I suppose you have already installed Python.
Install NLTK
On Linux/Mac, run the following command terminal:
For Python 2.x
sudo pip install nltk
For Python 3.x
sudo pip3 install nltk
After it is installed, you can verify its installation by running python on terminal:
python
>>> import nltk
>>>
If the import works without any error then nltk has been properly installed on your system.
For Windows users, you can follow the instructions provided here: http://www.nltk.org/install.html (This link also contains installation instructions for Linux & Mac users.)
Install NLTK Packages
Run python on terminal:
python
Then, import NLTK and run nltk.download()
>>> import nltk
>>> nltk.download()
This will open the NLTK downloader from where you can choose the corpora and models to download. You can also download all packages at once.
Simple Text Processing with NLTK
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
description = "A quick brown fox jumps over a lazy dog. The fox lives in the jungle. The dog lives in the kennel."
Convert raw text to nltk tokens
tokens = word_tokenize(description)
print (tokens)
'''
Output:
['A', 'quick', 'brown', 'fox', 'jumps', 'over', 'a', 'lazy', 'dog', '.', 'The', 'fox', 'lives', 'in', 'the', 'jungle', '.', 'The', 'dog', 'lives', 'in', 'the', 'kennel', '.']
'''
Convert tokens to nltk text format
text = nltk.Text(tokens)
print (text)
'''
Output:
<Text: A quick brown fox jumps over a lazy...>
'''
Search for any word in the text description
Concordance view will show the searched word along with some context related to that word
concordance = text.concordance('fox')
print (concordance)
'''
Output:
Displaying 2 of 2 matches:
fox jumps over a lazy dog . The fox lives
fox lives in the jungle . The dog lives i
'''
Output similar word as the searched word
Similar words mean what other words appear in a similar range of contexts.
similar = text.similar('quick')
print (similar)
Count the number of tokens in the text
Tokens include words and punctuation symbols.
token_count = len(text)
print (token_count)
'''
Output:
24
'''
Get unique tokens only by removing repeated tokens
unique_tokens = set(text)
print (unique_tokens)
'''
Output:
set(['A', 'brown', 'lazy', 'the', 'jumps', 'fox', 'dog', '.', 'lives', 'a', 'in', 'quick', 'The', 'over', 'kennel', 'jungle'])
'''
Count the number of unique tokens
unique_token_count = len(unique_tokens)
print (unique_token_count)
'''
Output:
16
'''
Sort tokens alphabetically
sorted_unique_tokens = sorted(unique_tokens)
print (sorted_unique_tokens)
'''
Output:
['.', 'A', 'The', 'a', 'brown', 'dog', 'fox', 'in', 'jumps', 'jungle', 'kennel', 'lazy', 'lives', 'over', 'quick', 'the']
'''
Lexical Diversity
Lexical Diversity = Ratio of unique tokens to the total number of tokens
len(set(text)) / len(text)
lexical_diversity = float(unique_token_count) / float(token_count)
print (lexical_diversity)
'''
Output:
0.666666666667
'''
Total number of occurrence of any particular word
word_count = text.count('dog')
print (word_count)
'''
Output:
2
'''
Percentage of any particular word in the whole text
100 * (Total count of the particular word) / (Total number of tokens in the text)
token_percentage = 100 * float(word_count) / float(token_count)
print (token_percentage)
'''
Output:
8.33333333333
'''
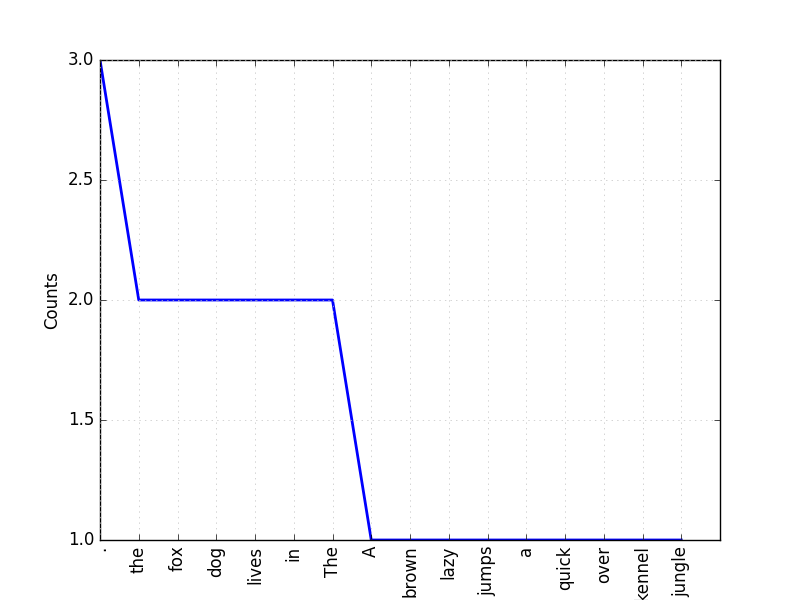
Frequency Distribution
Frequency (Number of occurence) of each vocabulary item in the text.
frequency_distribution = nltk.FreqDist(text)
print (frequency_distribution)
'''
Output:
<FreqDist with 16 samples and 24 outcomes>
'''
print (frequency_distribution.most_common(10))
'''
Output:
[('.', 3), ('the', 2), ('fox', 2), ('dog', 2), ('lives', 2), ('in', 2), ('The', 2), ('A', 1), ('brown', 1), ('lazy', 1)]
'''
Freqency Distribution Plot
print (frequency_distribution.plot())
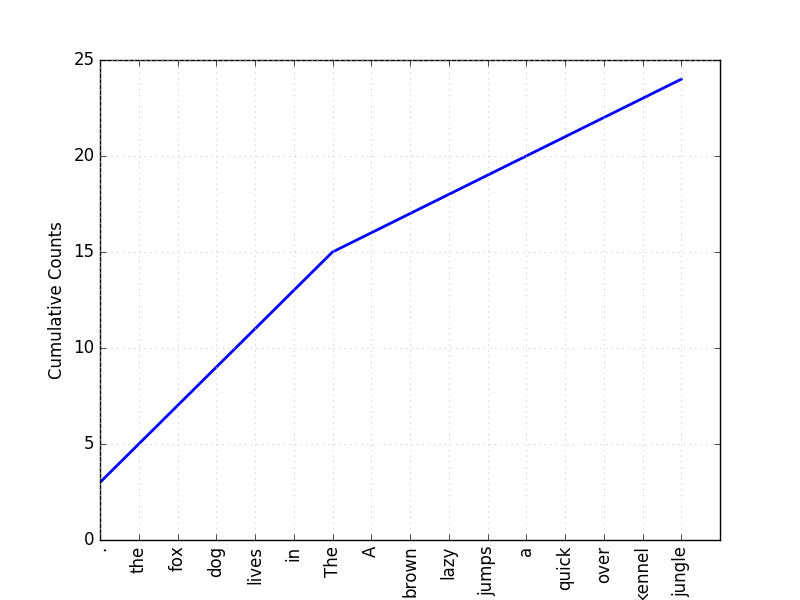
Cumulative Frequency Distribution Plot
Cumulative Frequency = Running total of absolute frequency
Running total means the sum of all the frequencies up to the current point.
Example:
Suppose, there are three words X, Y, and Z.
And their respective frequency is 1, 2, and 3.
This freqency is their absolute frequency.
Cumulative freqency of X, Y, and Z will be as follows:
X -> 1
Y -> 2+1 = 3
Z -> 3+3 = 6
print (frequency_distribution.plot(cumulative=True))
Collocations
Collocations = multiple-words that occur commonly
BIGRAMS
from nltk.collocations import BigramAssocMeasures, BigramCollocationFinder
bigram_measures = BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(tokens)
Finding the 10 best bigrams in the text
Here, scoring of ngrams is done by PMI (pointwise mutual information) method.
best_bigrams = finder.nbest(bigram_measures.pmi, 10)
print (best_bigrams)
'''
Output:
[('A', 'quick'), ('a', 'lazy'), ('jumps', 'over'), ('over', 'a'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumps'), ('in', 'the'), ('lazy', 'dog'), ('lives', 'in')]
'''
Here, scoring of ngrams is done by likelihood ratios method.
best_bigrams = finder.nbest(bigram_measures.likelihood_ratio, 10)
print (best_bigrams)
'''
Output:
[('in', 'the'), ('lives', 'in'), ('.', 'The'), ('A', 'quick'), ('a', 'lazy'), ('jumps', 'over'), ('over', 'a'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumps')]
'''
Frequency Distribution of Bigrams
print (finder.score_ngrams(bigram_measures.raw_freq))
'''
Output:
[(('.', 'The'), 0.08333333333333333), (('in', 'the'), 0.08333333333333333), (('lives', 'in'), 0.08333333333333333), (('A', 'quick'), 0.041666666666666664), (('The', 'dog'), 0.041666666666666664), (('The', 'fox'), 0.041666666666666664), (('a', 'lazy'), 0.041666666666666664), (('brown', 'fox'), 0.041666666666666664), (('dog', '.'), 0.041666666666666664), (('dog', 'lives'), 0.041666666666666664), (('fox', 'jumps'), 0.041666666666666664), (('fox', 'lives'), 0.041666666666666664), (('jumps', 'over'), 0.041666666666666664), (('jungle', '.'), 0.041666666666666664), (('kennel', '.'), 0.041666666666666664), (('lazy', 'dog'), 0.041666666666666664), (('over', 'a'), 0.041666666666666664), (('quick', 'brown'), 0.041666666666666664), (('the', 'jungle'), 0.041666666666666664), (('the', 'kennel'), 0.041666666666666664)]
'''
Ignore all bigrams that occur less than 2 times in the text
finder.apply_freq_filter(2)
best_bigrams = finder.nbest(bigram_measures.pmi, 10)
print (best_bigrams)
'''
[('in', 'the'), ('lives', 'in'), ('.', 'The')]
'''
TRIGRAMS
from nltk.collocations import TrigramAssocMeasures, TrigramCollocationFinder
trigram_measures = TrigramAssocMeasures()
finder = TrigramCollocationFinder.from_words(tokens)
Finding the 10 best trigrams in the text
Here, scoring of ngrams is done by PMI (pointwise mutual information) method.
best_trigrams = finder.nbest(trigram_measures.pmi, 10)
print (best_trigrams)
'''
Output:
[('A', 'quick', 'brown'), ('jumps', 'over', 'a'), ('over', 'a', 'lazy'), ('a', 'lazy', 'dog'), ('brown', 'fox', 'jumps'), ('fox', 'jumps', 'over'), ('quick', 'brown', 'fox'), ('in', 'the', 'jungle'), ('in', 'the', 'kennel'), ('lives', 'in', 'the')]
'''
Here, scoring of ngrams is done by likelihood ratios method.
best_trigrams = finder.nbest(trigram_measures.likelihood_ratio, 10)
print (best_trigrams)
'''
Output:
[('lives', 'in', 'the'), ('in', 'the', 'jungle'), ('in', 'the', 'kennel'), ('The', 'dog', 'lives'), ('The', 'fox', 'lives'), ('dog', 'lives', 'in'), ('fox', 'lives', 'in'), ('A', 'quick', 'brown'), ('jumps', 'over', 'a'), ('over', 'a', 'lazy')]
'''
Accessing Text Corpora
Text Corpus = Large collection of text
Text Corporas can be downloaded from nltk with nltk.download() command. It’s mentioned at the beginning of this article.
To access any text corpora, it should be downloaded first.
Here are the basic functions that can be used with the nltk text corpus:
fileids() = the files of the corpus
fileids([categories]) = the files of the corpus corresponding to these categories
categories() = the categories of the corpus
categories([fileids]) = the categories of the corpus corresponding to these files
raw() = the raw content of the corpus
raw(fileids=[f1,f2,f3]) = the raw content of the specified files
raw(categories=[c1,c2]) = the raw content of the specified categories
words() = the words of the whole corpus
words(fileids=[f1,f2,f3]) = the words of the specified fileids
words(categories=[c1,c2]) = the words of the specified categories
sents() = the sentences of the whole corpus
sents(fileids=[f1,f2,f3]) = the sentences of the specified fileids
sents(categories=[c1,c2]) = the sentences of the specified categories
abspath(fileid) = the location of the given file on disk
encoding(fileid) = the encoding of the file (if known)
open(fileid) = open a stream for reading the given corpus file
root = if the path to the root of locally installed corpus
readme() = the contents of the README file of the corpus
Movie Reviews Corpus
movie_reviews corpus contains 2K movie reviews with sentiment polarity classification. It’s compiled by Pang, Lee.
from nltk.corpus import movie_reviews
# print detailed description of the corpus
print (movie_reviews.readme())
print (len(movie_reviews.fileids())) # Output: 2000
print (movie_reviews.categories()) # Output: [u'neg', u'pos']
# get the first movie review of the movie_reviews corpus
movie_reviews_1 = movie_reviews.fileids()[0]
# raw text output
#print (movie_reviews.raw(fileids=[movie_reviews_1]))
# word tokens output
print (movie_reviews.words(fileids=[movie_reviews_1]))
'''
Output:
[u'plot', u':', u'two', u'teen', u'couples', u'go', ...]
'''
# sentence tokens output
print (movie_reviews.sents(fileids=[movie_reviews_1])) # word tokens output
'''
Output:
[[u'plot', u':', u'two', u'teen', u'couples', u'go', u'to', u'a', u'church', u'party', u',', u'drink', u'and', u'then', u'drive', u'.'], [u'they', u'get', u'into', u'an', u'accident', u'.'], ...]
'''
Stopwords Corpus
stopwords corpus contains the high-frequency words (words occurring frequently in any text document). In text processing, the document/text is filtered by removing the stop words.
from nltk.corpus import stopwords
print (stopwords.fileids())
'''
Output:
[u'arabic', u'danish', u'dutch', u'english', u'finnish', u'french', u'german', u'hungarian', u'italian', u'kazakh', u'norwegian', u'portuguese', u'romanian', u'russian', u'spanish', u'swedish', u'turkish']
'''
print (stopwords.words('english'))
#print (stopwords.words(fileids=['english']))
'''
Output:
[u'i', u'me', u'my', u'myself', u'we', u'our', u'ours', u'ourselves', u'you', u'your', u'yours', u'yourself', u'yourselves', u'he', u'him', u'his', u'himself', u'she', u'her', u'hers', u'herself', u'it', u'its', u'itself', u'they', u'them', u'their', u'theirs', u'themselves', u'what', u'which', u'who', u'whom', u'this', u'that', u'these', u'those', u'am', u'is', u'are', u'was', u'were', u'be', u'been', u'being', u'have', u'has', u'had', u'having', u'do', u'does', u'did', u'doing', u'a', u'an', u'the', u'and', u'but', u'if', u'or', u'because', u'as', u'until', u'while', u'of', u'at', u'by', u'for', u'with', u'about', u'against', u'between', u'into', u'through', u'during', u'before', u'after', u'above', u'below', u'to', u'from', u'up', u'down', u'in', u'out', u'on', u'off', u'over', u'under', u'again', u'further', u'then', u'once', u'here', u'there', u'when', u'where', u'why', u'how', u'all', u'any', u'both', u'each', u'few', u'more', u'most', u'other', u'some', u'such', u'no', u'nor', u'not', u'only', u'own', u'same', u'so', u'than', u'too', u'very', u's', u't', u'can', u'will', u'just', u'don', u'should', u'now', u'd', u'll', u'm', u'o', u're', u've', u'y', u'ain', u'aren', u'couldn', u'didn', u'doesn', u'hadn', u'hasn', u'haven', u'isn', u'ma', u'mightn', u'mustn', u'needn', u'shan', u'shouldn', u'wasn', u'weren', u'won', u'wouldn']
'''
Names Corpus
names corpus contains 8K male and female names. It’s compiled by Kantrowitz, Ross.
from nltk.corpus import names
print (names.fileids()) # Output: [u'female.txt', u'male.txt']
male_names = names.words('male.txt')
female_names = names.words('female.txt')
print (len(male_names)) # Output: 2943
print (len(female_names)) # Output: 5001
References:
1. http://www.nltk.org/book/ch01.html
2. http://www.nltk.org/howto/collocations.html
3. http://www.nltk.org/book/ch02.html
Hope this helps. Thanks.